How I use AI for software engineering
I’ve been reading many posts about how use people use AI, and how one approach is better than the other. I’ve been thinking about this a lot lately, and I’ve been experimenting with many different approaches. I’ve landed on a workflow that works well for me, which I want to share.
Firstly I don’t “vibe code”. I see AI as a powerful tool to improve my engineering capability. It is not a replacement for me. I also do not believe that we can use coding agents to do work fully AFK. I think a human should be in the loop for most of the work (but some work can be AFK, and that’s okay!). I see the agent as a teammate. I’m not trying to spawn multiple agents, run huge orchestrations, and essentially be the ‘big boss’. I still want to be part of the work.
I get better results when I use the agent before implementation: first to explore the idea, then to interrogate it, then to turn the decision into a plan the code can follow. The benefit is that I stay in the loop. By the time the agent writes code, I know what decision it is implementing, what tradeoffs I accepted, and what needs careful review.
I started doing this because I got tired of seeing large amounts of essentially sloppy code. The code often worked, but I struggled to explain why it had that shape. Some choices came from my requirements. Some came from the agent filling in gaps. During review, those looked the same.
This process works best for established codebases. It is hand-holdy, and it does not fit every task. Sometimes “please fix this bug” is enough. When the work is large, ambiguous, or headed for production, I stay close to the decisions and the code.
I won’t discuss reviewing code too much in this post. That deserves a post of its own.
From idea to decision
When you see
$PHRASEthis is a skill. Depending on your agent, you may invoke skills using$or/commands. Skills are basically pre-defined prompts that the agent can invoke.
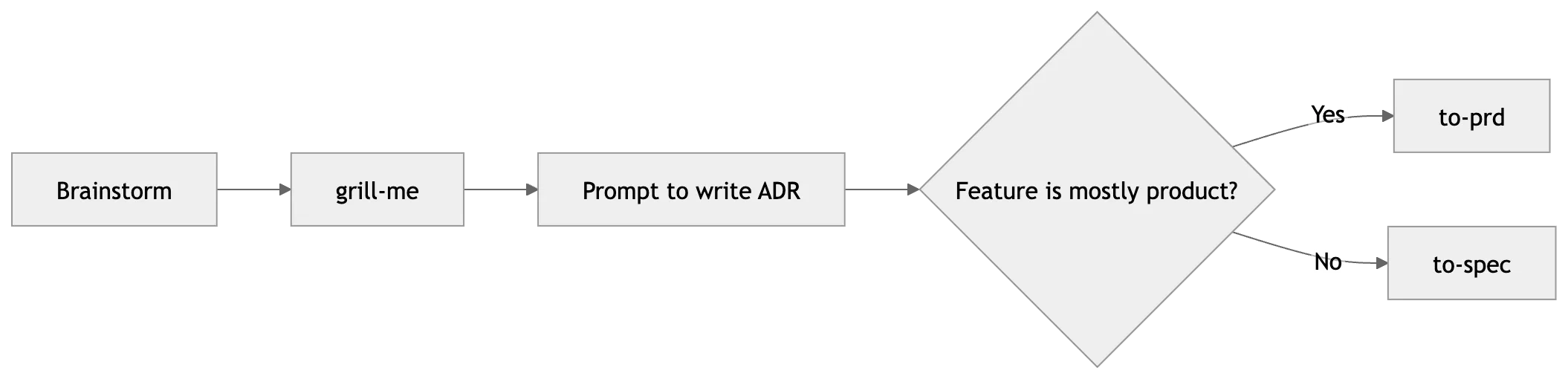
I start by turning a rough idea into a clearly defined request.
With $brainstorm, I test the rough version of the request: the repo boundaries, likely libraries, missing requirements, and places where I need a human decision. The request might start as “add Markdown export to the notes app.” Before I want code, I want to know whether the repo already has export logic, whether export should use raw editor state or rendered Markdown, and whether the feature touches permissions, filenames, or background jobs.
I use this phase to answer a few basic questions:
- What already exists that can help?
- How would this fit into the current repo?
- What libraries or frameworks should we use?
- What are we missing?
This catches bad work before files change. If the agent cannot explain how the feature fits the repo, I do not want it editing the repo yet.
Once I think the idea might hold up, I make the agent argue with it using $grill-me. The agent looks for ambiguity, hidden assumptions, missing constraints, and places where I am hand-waving. For the Markdown export example, that might surface questions about private notes, embedded images, frontmatter, filename collisions, and whether exported content should match the editor or the published view.
I keep going until the questions start repeating or the added precision stops changing the plan.
Unless explicitly instructed, most coding agents will not ask for more clarity or pushback on vague ideas. By default, they are instructed to be helpful and friendly. You want them to help you interrogate ideas and discuss tradeoffs, and
$grill-medoes this well.
From decision to code
After that, I write the decision down as an ADR. I simply ask the agent to write the decisions into an ADR. I do not start a new session at this point, I use the existing grilling session as context for the ADR.
ADRs are fantastic for capturing intent. A big part of this process is ensuring the agent and I are aligned on intent.
I use an ADR because both humans and models understand the format. It records the decision, the reasons behind it, and the tradeoffs I accepted. In the export example, the ADR might say: export from the rendered document, not the raw editor state, because users expect the downloaded Markdown to match what they previewed. That decision would rule out some simpler implementations and make the review easier later.
I keep these documents in a folder named after the task or issue identifier. I use Linear IDs, but you can use anything. You want to be able to map the folder to the task or idea that kicked off this work.
I edit the ADR myself. If the change affects teammates, I ask them to read it before I approve it. After approval, the agent can treat the decision as buildable. Only then do I ask the agent to turn the ADR into a plan the code can follow.
I use $to-prd when the change affects users. The PRD should explain who the change is for, what behaviour changes, and how I will know it worked.
I use $to-spec when the change is technical: devex work, migrations, architecture changes, or API boundaries. The spec should name the behaviours I am adding, changing, or removing.
When the PRD or spec is ready, I give the agent implementation constraints:
- Build the PRD or spec end to end.
- Do not stub functions or leave modules half-finished.
- Use
$tddfor backend logic and risky behaviour. - Skip tests that only assert mechanical wiring.
- Make the success criteria verifiable at the end.
I am more cautious with pure frontend TDD. I am still experimenting there. For backend changes, I want tests around the core behaviour, not 100% coverage for its own sake. For Markdown export, I would rather have tests for frontmatter, links, permissions, and filename collisions than a brittle component test that only proves a button exists.
These phases require you to read and digest a lot. I recommend taking a short break after reading the final spec, you may change your mind on some things!
Keeping the work reviewable
Agents have finite context windows. I have finite review capacity. Large tasks can work, but they increase the odds that the agent misses details, invents assumptions, or hands me a PR I cannot trust.
For larger work, I ask the agent to split the plan into slices after grilling. Each slice should fit in its own ADR, branch, and review. For the export feature, I might split the work into export semantics, backend generation, UI entry points, and cleanup. I do not want one PR that adds a button, rewrites the editor toolbar, changes permissions, and introduces a file generation service at the same time.
Sometimes I take one slice all the way from approval to implementation before approving the next one, because seeing the code often changes how I think the rest should work.
Once the work is done, I do not treat every document as permanent. The spec or PRD can be disposable; it existed to guide implementation. However, I keep the ADR because it records the decision, and that decision will still matter after the implementation details have changed.
After a few agent-written slices, I sometimes notice that I can navigate the feature but no longer like its shape. That is when I use $refactor-code for proposals. I want options for simplifying the code, improving file layout, or clarifying relationships between modules. Then I pick the changes worth making. Cleanup is easier once I have seen the feature run inside the real codebase.
I do the same for architecture work. When I see tight coupling, awkward boundaries, or a missing pattern, I use $improve-codebase-architecture for recommendations. I want options and tradeoffs before I let the agent change the code.
I usually do this on a separate branch from the main feature branch. That keeps cleanup from blocking the feature, and makes it easy to throw the experiment away.
I recommend creating new session between each phase. Large context windows can lead to lower quality, and auto-compaction will sometimes drop vital information.
The skills I use
$superpowers:brainstormturns a loose idea into repo-aware constraints, open questions, and possible approaches.$mattpocock:grill-meturns those approaches into sharper decisions by pushing on ambiguity, tradeoffs, and missing requirements.$mattpocock:grill-with-docsis great if you already have an ADR or spec you want to maintain.$mattpocock:to-prdturns an approved ADR into user stories, success criteria, and acceptance criteria.$chrisetheridge:to-specturns an approved ADR into technical behaviours: what changes, what stays the same, and what needs to be removed.$mattpocock:tddturns the PRD or spec into implementation with TDD.- Optional:
$chrisetheridge:refactor-codeturns working code into cleanup options after the feature exists. - Optional:
$mattpocock:improve-codebase-architectureturns deeper design problems into architecture recommendations and tradeoffs. - Optional:
$chrisetheridge:agent-doctorturns repeated agent confusion into better repo context.
You do not need these exact skills to use the same workflow. The important part is that each command has a clear job and leaves behind something I can read, question, approve, or reject before the agent moves on.
Model choice
I do not treat model choice as a substitute for process.
I use GPT 5.5 on medium reasoning for most of this. I do not usually reach for high or xhigh reasoning. If I feel like I need that much reasoning for ordinary feature work, I treat it as a smell: the architecture may be too complex, the task may be under-specified, or the repo context may be poor.
I have tried using smaller models for implementation after planning with a stronger model, but I found myself paying the cost elsewhere. The savings came back as stubbed functions, incomplete modules, and extra rounds of “this is broken, fix it.” For the way I work, better first-pass quality is worth the tokens.
Code still has a cost
I don’t want to make the process working with AI overly formal.
I am more productive with AI, and I build things I would not have attempted without it. For prototypes, I still move fast and stay flexible. For production work, I want the agent to leave a trail: what we decided, what it built, what it tested, and what I need to review.
No Silver Bullet
I do not think my workflow is the right way to use AI for engineering. It is the version I ended up with after building with these tools, getting annoyed, and changing the process around them.
Fred Brooks described the underlying problem in No Silver Bullet: better tools can remove accidental complexity, but they do not remove the essential complexity of the thing you are building.
Agentic coding has the same shape. Agents can reduce accidental complexity: boilerplate, API glue, test scaffolding, refactors, migrations, documentation, and routine implementation work. The essential complexity remains: deciding what the system should do, which tradeoffs matter, which abstractions will last, how behaviour should compose, what failure modes you can accept, and how the design should evolve.
That is why I do not think there is a universal harness for this work. Some teams will like heavier systems such as OpenSpec or Spec Kit. I tried that style and found it too heavy for my workflow. You may have the opposite experience.
You have to use the tools on real work to find out. Try public skills. Try a framework. Write your own prompts. Notice where the agent saves time, where it creates review debt, and where your process starts getting in the way.
The setup that works is the one you shape through use. It should fit your codebase, your team, and the kinds of decisions you need to make. For me, that means ADRs, PRDs, specs, narrow skills, and reviewable slices. For you, it might be something else.
FAQ
Can you give me the workflow in a simple diagram?
Do you apply this to every task?
No. I only apply it to tasks that involve complexity.
This depends a lot on your team, repo, and the kind of features you’re adding. There is nothing wrong with using a simple prompt for simple tasks.
Should my initial brainstorm prompt include lots of context?
Yes. Add as much as you can think of in the initial prompt:
- constraints
- solution ideas
- architecture design
- existing code
- relevant edge cases
- prior decisions
Every bit helps.
What about existing ADRs or specs that need to be extended?
Use grill-with-docs and specify the existing documents.
The process is the same as grill-me, except the agent updates the documents as you answer questions.
How do I decide between to-prd and to-spec?
There will not always be a clean distinction.
I recommend using both, reading the documents, and then deciding which one feels best for the task.
What do we do with specs once done?
Throw them away, but only once the code is merged into your base branch.
Until then, specs help reviewers understand the changes, and AI review tools can compare the code against specs and ADRs.